Utilisation du format Parquet avec Python illustré à partir de quelques exemples
Tutoriel Python
Author
Lino Galiana
Ce tutoriel n’est pas encore fini, il sera progressivement enrichi
Ce tutoriel vise à offrir une approche complémentaire au guide d’utilisation des données du recensement au format Parquet publié sur https://ssphub.netlify.app pour accompagner la diffusion de celles-ci par l’Insee.
Il s’agit d’un tutoriel préparé pour l’atelier tuto@mate à l’EHESS le 5 novembre 2024. Ce tutoriel est exclusivement en R. Les slides de la présentation sont disponibles ci-dessous:
Note
Pour retrouver une version R équivalente, c’est ici.
Dérouler les slides ci-dessous ou cliquer ici pour afficher les slides en plein écran.
Il propose des exemples variés pour illustrer la simplicité d’usage du format Parquet. Parmi ceux-ci, à partir du recensement de la population:
Liste des exemples à venir
Librairies utilisées
Ce tutoriel utilisera plusieurs librairies Python. Celles-ci peuvent être importées ainsi
pip install -r requirements.txt
Téléchargement des fichiers
Pour commencer, nous allons télécharger les fichiers depuis internet pour limiter les échanges réseaux. Comme nous le verrons ultérieurement, ce n’est en fait pas indispensable car duckdb optimise les données téléchargées à chaque requête.
Voir le code pour télécharger les données
import requestsimport osfrom tqdm import tqdmfrom pathlib import PathPath("data").mkdir(parents=True, exist_ok=True)def download_file(url: str, filename: str) ->None:try: response = requests.get(url, stream=True) response.raise_for_status()# Récupérer la taille totale du fichier depuis les headers (si disponible) total_size =int(response.headers.get('content-length', 0)) block_size =1024# 1 Kilobyte# Afficher un message si le content-length n'est pas disponibleif total_size ==0:print(f"Impossible de déterminer la taille du fichier {filename}, téléchargement sans barre de progression.")# Configuration de la barre de progression progress_bar = tqdm(total=total_size, unit='iB', unit_scale=True, desc=filename) if total_size >0elseNone# Écrire le contenu dans le fichierwithopen(filename, 'wb') asfile:for chunk in response.iter_content(chunk_size=block_size):if progress_bar: progress_bar.update(len(chunk))file.write(chunk)if progress_bar: progress_bar.close()print(f"Fichier téléchargé avec succès: {filename}")except requests.exceptions.RequestException as e:print(f"Le téléchargement a échoué: {e}")filename_table_logement ="data/RPlogement.parquet"filename_table_individu ="data/RPindividus.parquet"files_to_download = {"logements": {"url": "https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-logements-ordinaires-en-2020-1/20231023-123618/fd-logemt-2020.parquet", "filename": filename_table_logement},"individus": {"url": "https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet", "filename": filename_table_individu},"documentation_logement": {"url": "https://www.data.gouv.fr/fr/datasets/r/c274705f-98db-4d9b-9674-578e04f03198", "filename": "data/RPindividus_doc.csv"},"documentation_individus": {"url": "https://www.data.gouv.fr/fr/datasets/r/1c6c6ab2-b766-41a4-90f0-043173d5e9d1", "filename": "data/RPlogement_doc.csv"},"table_bpe": {"url": "https://minio.lab.sspcloud.fr/lgaliana/diffusion/BPE23.parquet", "filename": "data/BPE2023.parquet"}}# Boucle pour télécharger les fichiers avec des noms personnalisés (s'ils ne sont pas déjà enregistrés)for key, file_info in files_to_download.items(): url = file_info["url"] filename = file_info["filename"]# Débogage : vérifier si le fichier existe déjàif os.path.exists(filename):print(f"Le fichier {filename} existe déjà, pas de téléchargement.")else:print(f"Téléchargement de {filename}...") download_file(url, filename)
Nous aurons également besoin pour quelques illustrations d’un fond de carte des départements. Celui-ci peut être simplement récupéré grâce au packagecartiflette1
from plotnine import*( ggplot(departements) + geom_map() + theme_void())
Création de la base de données
En principe, duckdb fonctionne à la manière d’une base de données. Autrement dit, on définit une base de données et effectue des requêtes (SQL ou verbes tidyverse) dessus. Pour créer une base de données, il suffit de faire un read_parquet avec le chemin du fichier.
La base de données se crée tout simplement de la manière suivante:
import duckdbduckdb.sql(f""" FROM read_parquet(\"{filename_table_logement}\") SELECT * LIMIT 5 """).to_df()
COMMUNE
ARM
IRIS
ACHL
AEMM
AEMMR
AGEMEN8
ANEM
ANEMR
ASCEN
...
STOCD
SURF
TACTM
TPM
TRANSM
TRIRIS
TYPC
TYPL
VOIT
WC
0
01001
ZZZZZ
ZZZZZZZZZ
A11
1993
8
65
29
4
2
...
10
6
21
Z
Z
ZZZZZZ
1
1
2
Z
1
01001
ZZZZZ
ZZZZZZZZZ
C113
2013
9
40
9
2
2
...
10
6
11
1
5
ZZZZZZ
2
1
2
Z
2
01001
ZZZZZ
ZZZZZZZZZ
C113
2013
9
65
9
2
2
...
21
4
21
Z
Z
ZZZZZZ
2
1
2
Z
3
01001
ZZZZZ
ZZZZZZZZZ
A12
1994
8
65
28
4
2
...
10
7
21
Z
Z
ZZZZZZ
1
1
1
Z
4
01001
ZZZZZ
ZZZZZZZZZ
C115
0
0
YY
999
99
Y
...
0
Y
YY
Y
Y
ZZZZZZ
Y
6
X
Z
5 rows × 69 columns
La chaîne d’exécution ressemble ainsi à celle-ci:
Les calculs ont lieu dans duckdb et le résultat est transformé en DataFramePandas avec la méthode to_df.
Le fait de passer par l’intermédiaire de duckdb et un fichier Parquet permet d’optimiser les besoins mémoire de Python. En effet, il n’est pas nécessaire d’ouvrir un fichier dans son ensemble, le transformer en objet Python pour n’utiliser qu’une partie des données. Nous verrons ultérieurement la manière dont les besoins mémoires sont minimisés grâce au combo duckdb & Parquet.
Enfin, nous pouvons importer les dictionnaires des variables qui pourront nous servir ultérieurement:
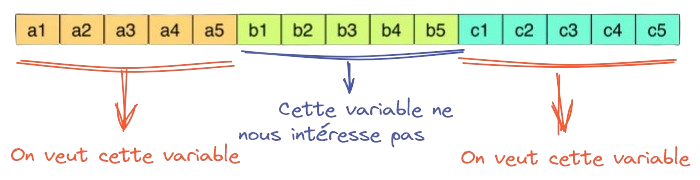
L’une des forces du format Parquet est de simplifier l’import de fichiers volumineux qui ne comportent que quelques colonnes nous intéressant. Par exemple, la table des individus comporte 88 colonnes, il est peu probable qu’une seule analyse s’intéresse à toutes celles-ci (ou elle risque d’être fort indigeste).
Comme cela est illustré dans ?@tip-optimisation-duckdb, la différence de volumétrie entre un fichier non filtré et un fichier filtré est importante.
Comprendre l’optimisation permise par Parquet et DuckDB
Pour réduire la volumétrie des données importées, il est possible de mettre en oeuvre deux stratégies:
N’importer qu’un nombre limité de colonnes
N’importer qu’un nombre limité de lignes
Comme cela a été évoqué dans les slides, le format Parquet est particulièrement optimisé pour le premier besoin. C’est donc généralement la première optimisation mise en oeuvre. Pour s’en convaincre on peut regarder la taille des données importées dans deux cas:
On utilise beaucoup de lignes mais peu de colonnes
On utilise beaucoup de colonnes mais peu de lignes
Pour cela, nous utilisons la fonction SQL EXPLAIN ANALYZE disponible dans duckdb. Elle décompose le plan d’exécution de duckdb, ce qui nous permettra de comprendre la stratégie d’optimisation. Elle permet aussi de connaître le volume de données importées lorsqu’on récupère un fichier d’internet. En effet, duckdb est malin: plutôt que de télécharger un fichier entier pour n’en lire qu’une partie, la librairie est capable de n’importer que les blocs du fichier qui l’intéresse.
Ceci nécessite l’utilisation de l’extension httpfs (un peu l’équivalent des library de R en duckdb). Elle s’installe et s’utilise de la manière suivante
duckdb.sql("INSTALL httpfs; LOAD httpfs;")
Demandons à DuckDB d’exécuter la requête “beaucoup de colonnes, pas beaucoup de lignes” et regardons le plan d’exécution et les informations données par DuckDB:
Voir le plan : “beaucoup de colonnes, pas beaucoup de lignes”
La comparaison de ces plans d’exécution montre l’intérêt de faire un filtre sur les colonnes : les besoins computationnels sont drastiquement diminués. Le filtre sur les lignes n’arrive que dans un second temps, une fois les colonnes sélectionnées.
Pourquoi seulement un rapport de 1 à 4 entre le poids des deux fichiers ? C’est parce que nos requêtes comportent toute deux la variable IPONDI (les poids à utiliser pour extrapoler l’échantillon à la population) qui est à haute précision là où beaucoup d’autres colonnes comportent un nombre réduit de modalités et sont donc peu volumineuses.
DuckDB propose également des fonctionnalités pour extraire des colonnes à travers des expressions régulières. Cette approche est également possible avec le tidyverse
duckdb.sql(f""" FROM read_parquet(\"{filename_table_individu}\") SELECT IPONDI AS poids, COLUMNS('.*AGE.*') LIMIT 10 """).to_df()
poids
AGED
AGER20
AGEREV
AGEREVQ
0
0.865066
74
79
73
70
1
4.987931
39
39
38
35
2
4.987931
9
10
8
5
3
5.013547
55
54
54
50
4
3.478368
1
2
0
0
5
3.478368
43
54
42
40
6
3.478368
38
39
37
35
7
1.003585
46
54
45
45
8
1.003585
16
17
15
15
9
0.984087
59
64
58
55
Requêtes sur les lignes (WHERE)
duckdb.sql(f""" FROM read_parquet("{filename_table_individu}") SELECT IPONDI, AGED, DEPT WHERE DEPT IN ('11', '31', '34') LIMIT 10 """).to_df()
IPONDI
AGED
DEPT
0
5.027778
59
11
1
5.027778
83
11
2
4.996593
50
11
3
4.996593
26
11
4
5.148676
9
11
5
5.148676
38
11
6
5.148676
49
11
7
5.000000
88
11
8
5.000000
88
11
9
5.297153
18
11
Les filtres sur les observations peuvent être faits à partir de critères sur plusieurs colonnes. Par exemple, pour ne conserver que les observations de la ville de Nice où la date d’emménagement est postérieure à 2020, la requête suivante peut être utilisée :
duckdb.sql(f""" FROM read_parquet("{filename_table_logement}") SELECT * WHERE COMMUNE = '06088' AND AEMM > 2020 LIMIT 10 """).to_df()
COMMUNE
ARM
IRIS
ACHL
AEMM
AEMMR
AGEMEN8
ANEM
ANEMR
ASCEN
...
STOCD
SURF
TACTM
TPM
TRANSM
TRIRIS
TYPC
TYPL
VOIT
WC
0
06088
ZZZZZ
060880101
A11
2022
9
40
0
0
2
...
21
4
11
1
5
060421
3
2
1
Z
1
06088
ZZZZZ
060880101
A11
2021
9
40
1
0
2
...
10
2
11
1
6
060421
3
2
0
Z
2
06088
ZZZZZ
060880101
A12
2021
9
25
1
0
2
...
21
2
12
Z
Z
060421
3
2
0
Z
3
06088
ZZZZZ
060880101
A11
2021
9
40
1
0
2
...
21
3
11
1
5
060421
3
2
1
Z
4
06088
ZZZZZ
060880101
A11
2021
9
40
1
0
2
...
21
3
11
1
5
060421
3
2
1
Z
5
06088
ZZZZZ
060880101
A11
2021
9
40
1
0
2
...
21
2
11
1
2
060421
3
2
0
Z
6
06088
ZZZZZ
060880101
A11
2021
9
25
1
0
2
...
21
2
11
1
2
060421
2
2
0
Z
7
06088
ZZZZZ
060880101
A11
2021
9
40
1
0
2
...
21
2
11
1
2
060421
3
2
0
Z
8
06088
ZZZZZ
060880101
A11
2021
9
25
1
0
2
...
21
5
11
1
6
060421
3
2
1
Z
9
06088
ZZZZZ
060880101
A11
2021
9
55
1
0
2
...
21
3
12
Z
Z
060421
2
2
0
Z
10 rows × 69 columns
Statistiques agrégées
Exemples sans groupes
La fonction DISTINCT appliquée à la variable ARM permet d’extraire la liste des codes arrondissements présents dans la base de données.
query =f"""FROM read_parquet('{filename_table_logement}')SELECT DISTINCT ARMWHERE NOT ARM LIKE '%ZZZZZ%'ORDER BY ARM"""result =", ".join(duckdb.sql(query).to_df()["ARM"])
Il est possible d’extraire des statistiques beaucoup plus raffinées par le biais d’une requête SQL plus complexe. Par exemple pour calculer le nombre d’habitants de Toulouse qui ont changé de logement en un an:
query =f"""FROM read_parquet("{filename_table_logement}")SELECT CAST(SUM(IPONDL * CAST(INPER AS INT)) AS INT) AS habitants_toulouse_demenagementWHERE COMMUNE = '31555' AND IRANM NOT IN ('1', 'Z') AND INPER != 'Y'"""duckdb.sql(query).to_df()
habitants_toulouse_demenagement
0
86364
Statistiques par groupe
SQL et dplyr permettent d’aller loin dans la finesse des statistiques descriptives mises en oeuvre. Cela sera illustré à l’aide de plusieurs exemples réflétant des statistiques pouvant être construites grâce à ces données détaillées.
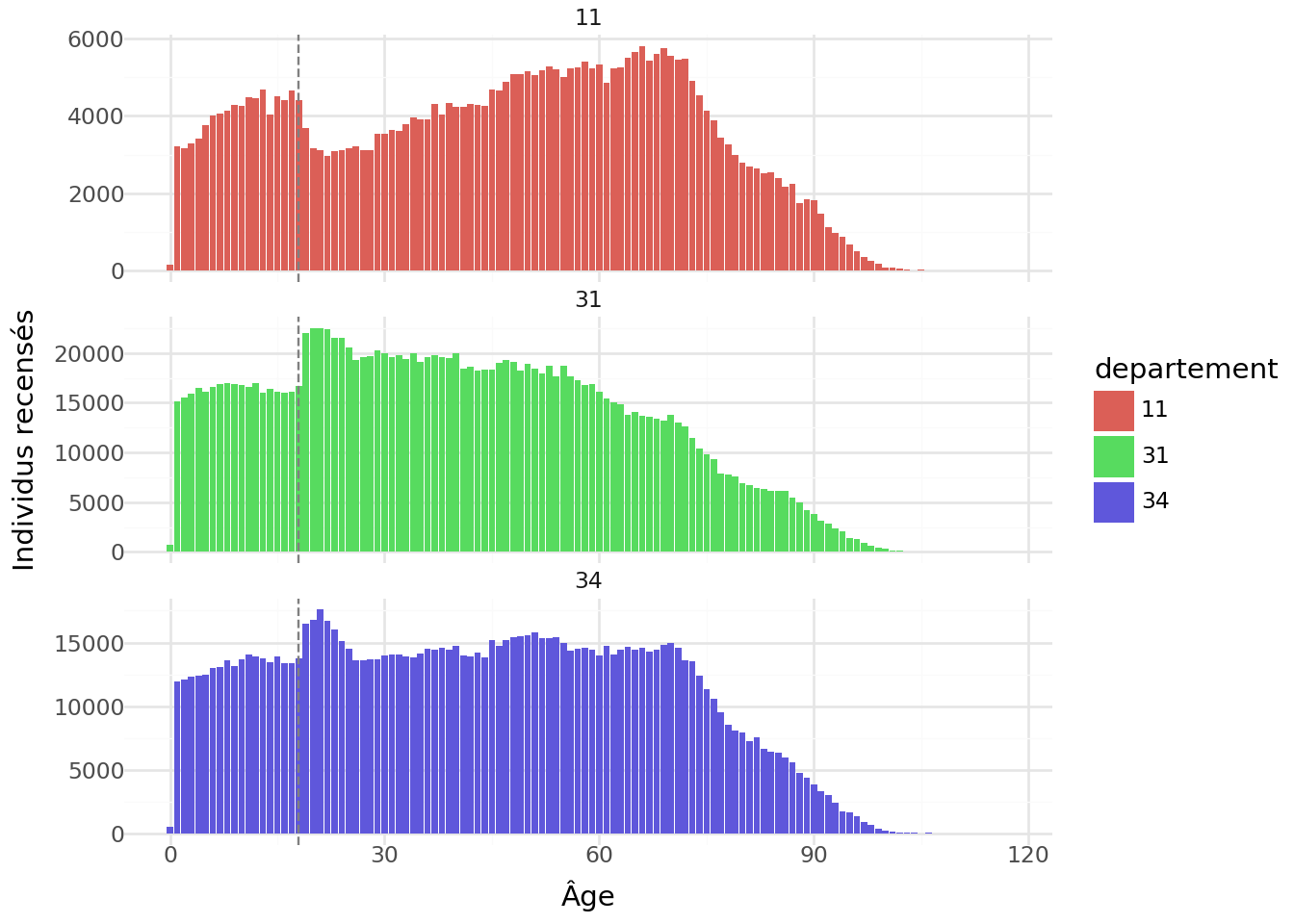
Exemple 1: pyramide des âges dans l’Aude, l’Hérault et le Gard
Le premier exemple est un comptage sur trois départements. Il illustre la démarche suivante:
On se restreint aux observations d’intérêt (ici 3 départements)
On applique la fonction summarise pour calculer une statistique par groupe, en l’occurrence la somme des pondérations
On retravaille les données
Ensuite, une fois que nos données sont récupérées dans R, on peut faire la figure avec ggplot
Listing 1: Pyramide des âges dans l’Aude, l’Hérault et le Gard
pyramide_ages = duckdb.sql(f""" FROM read_parquet("{filename_table_individu}") SELECT AGED, DEPT AS departement, SUM(IPONDI) AS individus WHERE DEPT IN ('11', '31', '34') GROUP BY AGED, DEPT ORDER BY DEPT, AGED """ ).to_df()# Create the plotplot = ( ggplot(pyramide_ages, aes(x='AGED', y='individus'))+ geom_bar(aes(fill='departement'), stat="identity")+ geom_vline(xintercept=18, color="grey", linetype="dashed")+ facet_wrap('~departement', scales="free_y", nrow=3)+ theme_minimal()+ labs(y="Individus recensés", x="Âge"))plot
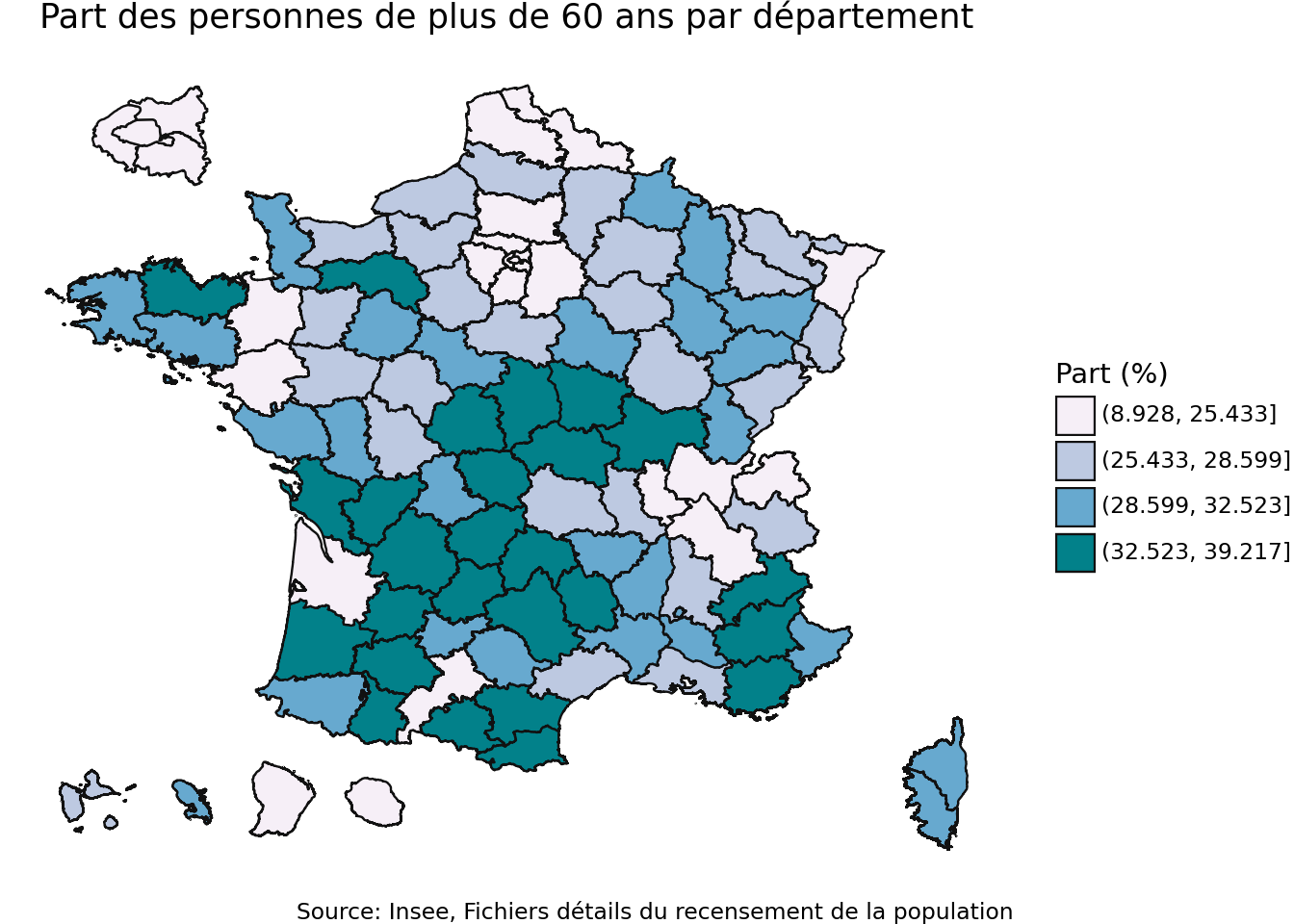
Exemple 2: répartition des plus de 60 ans par département
L’objectif de ce deuxième exemple est d’illustrer la construction d’une statistique un peu plus complexe et la manière de projeter celle-ci sur une carte.
Pour avoir la répartition des plus de 60 ans par département, quelques lignes de dplyr suffisent:
import pandas as pdimport duckdb# Query to calculate total population and population over 60part_population_60_plus = duckdb.sql(f""" FROM read_parquet("{filename_table_individu}") SELECT DEPT, SUM(IPONDI) AS total_population, SUM(CASE WHEN AGED > 60 THEN IPONDI ELSE 0 END) AS population_60_plus GROUP BY DEPT """).to_df()# Calculate percentage of population over 60part_population_60_plus['pourcentage_60_plus'] = ( part_population_60_plus['population_60_plus'] / part_population_60_plus['total_population'] *100)# Display the resultpart_population_60_plus
DEPT
total_population
population_60_plus
pourcentage_60_plus
0
15
1.443207e+05
51594.268330
35.749725
1
16
3.515488e+05
115884.210207
32.963901
2
22
6.034105e+05
201335.103066
33.366193
3
24
4.131804e+05
153404.822502
37.127805
4
45
6.827497e+05
178146.809475
26.092549
...
...
...
...
...
95
29
9.170858e+05
277937.304226
30.306575
96
2A
1.607982e+05
49182.373626
30.586396
97
60
8.296354e+05
191667.259892
23.102590
98
61
2.782949e+05
93452.962115
33.580552
99
77
1.428738e+06
287073.307178
20.092786
100 rows × 4 columns
Il ne reste plus qu’à projeter ceci sur une carte. Pour cela, un join à notre fond de carte suffit. Comme les données sont agrégées et déjà dans R, il n’y a rien de spécifique à duckdb ici.
Association de part_population_60_plus au fond de carte des départements
# Joindre les données au fond de carte des départementsdepartements_60_plus_gpd = ( departements .merge( part_population_60_plus, left_on ="INSEE_DEP", right_on ="DEPT" ))
Finalement, il ne reste plus qu’à produire la carte:
( ggplot(departements_60_plus_gpd) + geom_map(aes(fill ="pourcentage_60_plus_d")) + scale_fill_brewer(palette ="PuBuGn", direction =1) + theme_void() + labs( title ="Part des personnes de plus de 60 ans par département", caption ="Source: Insee, Fichiers détails du recensement de la population", fill ="Part (%)" ))
Si on préfère représenter ceci sous forme de tableau, on peut utiliser le packagegreat tables. Cela nécessite quelques manipulations de données en amont.