Enjeux et méthodes de la reproductibilité scientifique
Lino Galiana 
Insee
29 mai 2026
Contexte
- “Crise de la reproductibilité” durable dans la recherche
- Ioannidis (2005), Chang et Li (2017), Kapoor et Narayanan (2023)…
- Enjeu similaire dans l’industrie avec le problème du mur de la production (Davenport et Malone 2021)
- Facteurs multiples:
- Acculturation et incitations limités aux enjeux de reproductibilité ;
- Auditabilité limitée avec des données non partageables ;
- Complexification des projets avec un accès aux données par le biais de multiples fournisseurs ou infrastructures ;
- Recours à des logiciels propriétaires difficiles à auditer…
- Mouvement de la science ouverte et politique plus active des revues scientifiques pour plus de transparence
Exemple: la politique de l’AEA
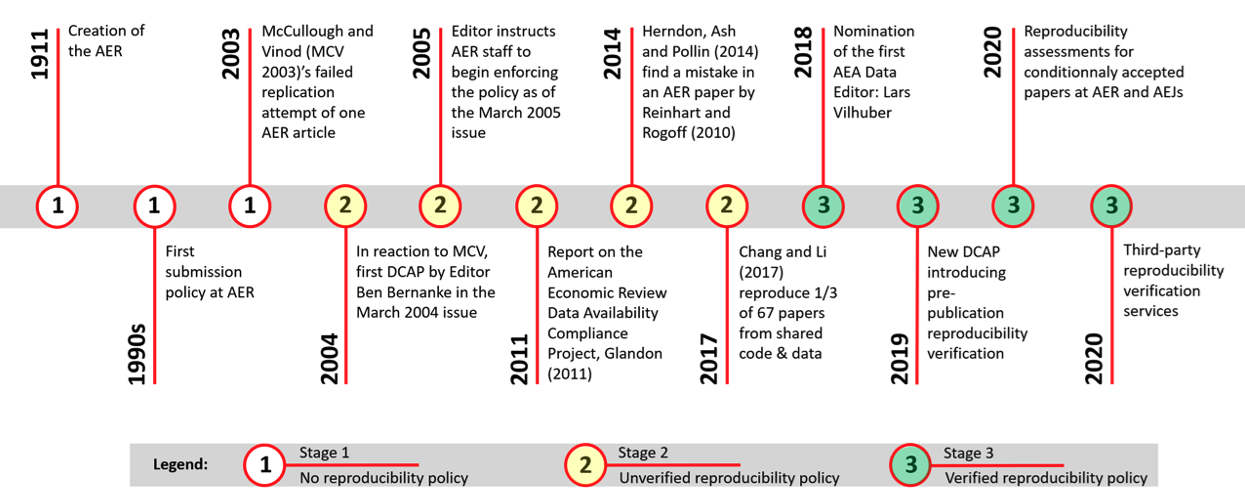
Plus de détails récents, dans AEA Data and code sharing policy et Vilhuber et Cavanagh (2025)
L’échelle de la reproductibilité

Source: Peng (2011)
- Une reproductibilité parfaite est coûteuse
Gitest un standard atteignable et efficient
Partage et transparence des données
- Beaucoup de données non partageables (secret industriel, confidentialité…)
- France : accès simplifié aux données pour les chercheurs avec le CASD
- Approches à plusieurs niveaux :
- Partage du protocole de collecte (sciences expérimentales)
- Données synthétiques
- Tiers de confiance (Pérignon et al. 2019)
- Sujet de bonnes pratiques dans le format des données sources et intermédiaires
Excel🔴,CSV🟠,Parquet🟢
- Si la réplication n’est pas toujours possible, on peut au moins viser la reproductiblité
Le début des problèmes
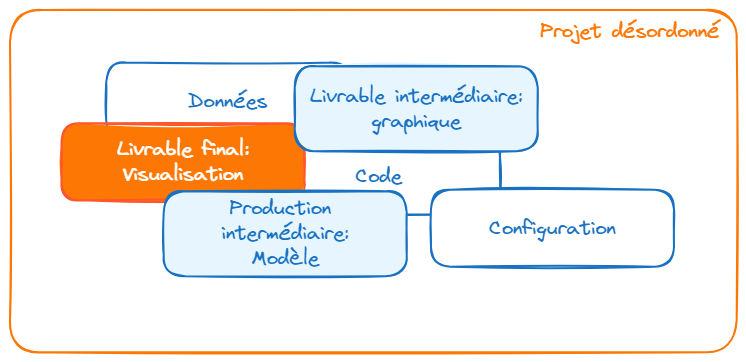
Le premier pas
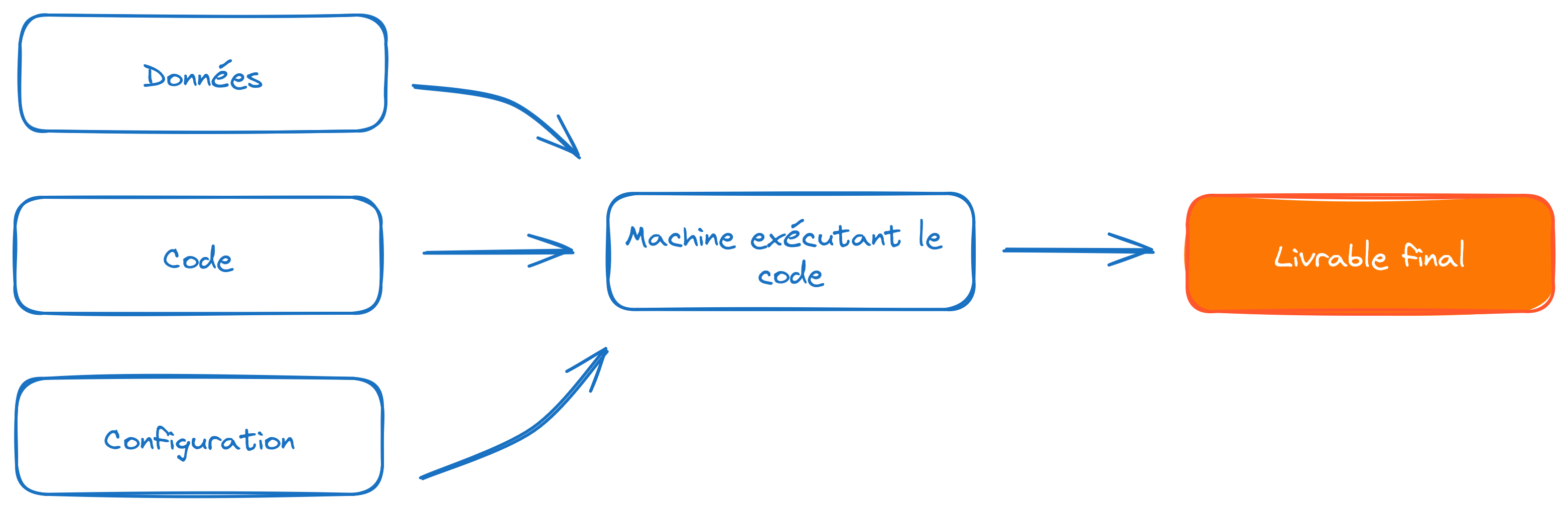
Partage et transparence du code
Niveau 0: versionner et partager son code
Git, la première des bonnes pratiques:- Fiabilise l’évolution d’un projet avec du code
- Oblige à se poser la question des bonnes pratiques
- Permet de gérer la temporalité complexe d’un projet de recherche (tests, retours en arrière, etc.)
Githubet l’open source, une démarche de transparence scientifique:- Partager son code de manière proactive en améliore la qualité
- Possibilité de recevoir des feedbacks améliore la qualité
- Galerie pour valoriser un projet
Partage et transparence du code
Premier niveau: lisibilité du code
“Le code est plus souvent lu qu’utilisé”. Guido Van Rossum
- Un outil de communication de la méthodologie
- et de réplication de celle-ci (ex : package d’économétrie)
- Conventions communautaires : tidyverse style guide (), PEP8 et PEP257 ()
Partage et transparence du code
Deuxième niveau: lisibilité de la structure
Plus de détails dans un cours de mise en production de l’ENSAE (Avouac et Galiana 2025)
├── report.ipynb
├── correlation.png
├── data.csv
├── data2.csv
├── fig1.png
├── figure 2 (copy).png
├── report.pdf
├── partial data.csv
├── script.py
└── script_final.py├── data
│ ├── raw
│ │ ├── dpe_logement_202103.csv
│ │ └── dpe_logement_202003.csv
│ └── interim
│ └── dpe_logement_merged_preprocessed.csv
├── notebooks
│ └── report.ipynb
├── src
| ├── main.R
| ├── preprocessing.R
│ └── generate_plots.R
└── reports
├── report.pdf
└── figures
├── histogram_energy_diagnostic.png
├── barplot_consumption_pcs.png
├── correlation_matrix.png
└── correlation.pngPartage et transparence du code
Troisième niveau: d’où vient ce chiffre ?
Git, la première des bonnes pratiques- Mais ne suffit pas lorsqu’on a plus du code dans un projet
- “Literate programming” (Knuth 1984) = mélanger texte et code:
- Jongler entre le code et le papier dans \(\LaTeX\): source d’erreur
Jupyter notebook: intéressant (Perkel 2018) mais potentiels problèmes de reproductibilité (Samuel et Mietchen 2023). - Meilleur outil :
Quarto!
Partage et transparence de la configuration
Un projet lisible, structuré et versionné suffit-il à assurer la reproductibilité ?

Partage et transparence de la configuration
- De nombreux éléments d’environnement peuvent faire qu’un code est non réplicable:
- Environnement logiciel, secrets d’authentification, etc.
- Certains sont partageables, d’autres non (ex: jetons d’API 👮)
- (Auto)documenter dans le code (variables d’environnement et
.envou.Renviron)
- Solution 1 : environnements virtuels
- Recette de construction de l’environnement permettant de faire tourner le code
- Solution technique:
venvouuv(),renven ()
- Solution 2: la conteneurisation
- Partager la recette de construction de l’ordinateur ayant permis de faire tourner le code (solution technique:
Docker) - Plutôt orienté utilisation industrielle mais intéressant pour certains projets de recherche
- Partager la recette de construction de l’ordinateur ayant permis de faire tourner le code (solution technique:
Conclusion
- On a des outils techniques à utiliser pour résoudre la crise de la reproductibilité:
- Socle minimal est atteignable simplement,
- Etapes suivantes selon les projets.
- Mais aussi et surtout une démarche à adopter
- Aux bénéfices nombreux:
- Moindre coût de maintenance,
- Plus de transparence, de réutilisation…
Références
Avouac, Romain, et Lino Galiana. 2025. Mise en production de projets data science. Cours à l’ENSAE. https://doi.org/10.5281/zenodo.17486259.
Chang, Andrew C., et Phillip Li. 2017. « A Preanalysis Plan to Replicate Sixty Economics Research Papers That Worked Half of the Time ». American Economic Review 107 (5): 60‑64. https://doi.org/10.1257/aer.p20171034.
Colliard, Jean-Edouard, Christophe Hurlin, et Christophe Pérignon. 2023. « The economics of computational reproducibility ». HEC Paris Research Paper No. FIN-2019-1345.
Davenport, Thomas, et Katie Malone. 2021. « Deployment as a Critical Business Data Science Discipline ». Harvard Data Science Review 3 (1).
Ioannidis, John PA. 2005. « Why most published research findings are false ». PLoS medicine 2 (8): e124.
Kapoor, Sayash, et Arvind Narayanan. 2023. « Leakage and the reproducibility crisis in machine-learning-based science ». Patterns 4 (9).
Knuth, D. E. 1984. « Literate Programming ». The Computer Journal 27 (2): 97‑111. https://doi.org/10.1093/comjnl/27.2.97.
Peng, Roger D. 2011. « Reproducible research in computational science ». Science 334 (6060): 1226‑27.
Pérignon, Christophe, Kamel Gadouche, Christophe Hurlin, Roxane Silberman, et Eric Debonnel. 2019. « Certify reproducibility with confidential data ». Science 365 (6449): 127‑28.
Perkel, Jeffrey M. 2018. « Why Jupyter is data scientists’ computational notebook of choice ». Nature 563 (7732): 145‑47.
Samuel, Sheeba, et Daniel Mietchen. 2023. Computational reproducibility of Jupyter notebooks from biomedical publications. https://arxiv.org/abs/2308.07333.
Vilhuber, Lars, et Jack Cavanagh. 2025. « Report of the AEA Data Editor ». AEA Papers and Proceedings 115 (mai): 944‑57. https://doi.org/10.1257/pandp.115.944.