html`
<div style="display: flex; flex-direction: column; gap: 1rem;">
<!-- Search bar at the top -->
<div>${viewof search}</div>
<!-- Two-column block -->
<div style="display: grid; grid-template-columns: 1fr 1fr; gap: 1rem; backgroundColor: '#293845';">
<div>${produce_histo(dvf)}</div>
<div>${viewof table_dvf}</div>
</div>
</div>
`Le format Parquet pour la diffusion de données
Un choix technique au service des utilisateurs
Cédric Bobinec
Insee, Pôle Didoc
Lino Galiana 
Insee, Direction des statistiques démographiques et sociales
26 novembre 2025
Contexte
- Fichiers détail anonymisés diffusés sur insee.fr:
- une ligne par observation (un logement, un individu, etc.)
- Des produits phares: Sirene, Recensement de la population, Base Tous salariés, fichier des prénoms, décès, etc.
- Destinés à des utilisateurs avancés:
- Construire d’autres croisements ou regroupements que ceux proposés sur insee.fr
- Des précautions d’emploi à respecter (pondérations)
Avant Parquet: le recensement de la population (RP)
- Jusqu’à 100 variables et 25 millions de lignes
- Diffusion en CSV zippés ou
DBase(format propriétaire)
Exemple: Recensement de la Population
- Ficher détail :
CSV: > 4GoParquet: < 500Mo
Enjeux
- Plusieurs approches pour diffuser des données:
- Fichier vs API
- Le choix d’un mode de diffusion répond à un arbitrage entre plusieurs critères :
- Public cible
- Finalité (traitement, analyse, diffusion)
- Volumétrie
- Interopérabilité
Limites des formats usuels
- Les formats usuels (
CSV,JSON,XML) sont utiles pour :- Le traitement de faibles volumes de données
- La diffusion de données simples
- Limités pour le traitement de données volumineuses ou complexes
- Non-compressés : fichiers lourds
- Orientés ligne : peu adaptés aux traitements analytiques
- Pas de métadonnées : problèmes à la lecture
Parquet: quel avantage ?
- Un format interopérable :
- Très bien intégré aux outils des utilisateurs experts (, ou grâce à
ArrowetDuckDB)
- Très bien intégré aux outils des utilisateurs experts (, ou grâce à
- Un format optimisé :
- Lecture et traitement du fichier accélérés
- Un format fiable :
- Données conformes à l’intention du producteur…
Quel gain de confort pour les utilisateurs ?
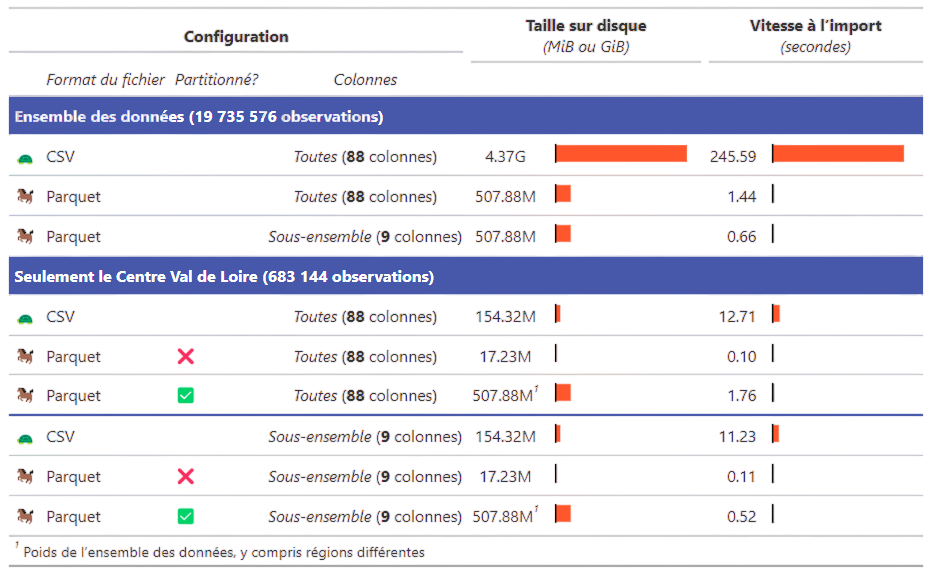
Pour en savoir plus, formation de l’Insee aux bonnes pratiques et
Un guide pour accompagner la diffusion
- Accompagner les utilisateurs avancés ;
- Donner envie à de nouveaux utilisateurs d’explorer ;
- Illustrer la richesse des données avec des exemples ;
- Faire comprendre que ce choix technique innovant est au service du confort des utilisateurs.
Des exemples s’appuyant sur les outils des utilisateurs
Classer les départements en fonction du nombre de centenaires recensés
| individus_recenses | DEPT |
|---|---|
| 1 334 | 75 |
| 1 175 | 13 |
| 963 | 69 |
| 952 | 06 |
Parquet fin 2025
- Nombreux jeux de données volumineux diffusés en
Parquet:- Insee: Sirene, REU, RP, BPE, etc.
- Format bientôt dans le catalogue de données (Melodi)
- SSM: bases statistiques de la délinquance
data.gouv: beaucoup de conversions enParquet
- Quelques bonnes pratiques à mettre en oeuvre:
- Optimiser les types des variables, trier les observations…
- Mauviere (2024) donne de nombreux conseils utiles.
Conclusion: quelles perspectives pour la diffusion de données ?
- Un complément aux API de données
- Approche simple et efficace pour la récupération de données brutes
- Permet des alternatives à
ShinyouStreamlitpour les portails de dataviz- Des dataviz complexes sur des serveurs statiques avec
DuckDB🦆 dans le navigateur
- Des dataviz complexes sur des serveurs statiques avec
viewof search = Inputs.select(cog, {format: x => x.LIBELLE, value: cog.find(t => t.LIBELLE == "Grasse")})
cog = db.query(`SELECT * FROM read_csv_auto("https://minio.lab.sspcloud.fr/lgaliana/data/python-ENSAE/cog_2023.csv") WHERE DEP == '06'`)
dvf = db.query(query)
db = DuckDBClient.of({})
query = `
FROM read_parquet('https://minio.lab.sspcloud.fr/projet-formation/nouvelles-sources/data/geoparquet/dvf.parquet')
SELECT
CAST(date_mutation AS date) AS date,
valeur_fonciere, code_commune,
longitude, latitude, valeur_fonciere AS valeur_fonciere_bar
WHERE code_commune = '${search.COM}'
`viewof table_dvf = Inputs.table(dvf, {columns: ["date", "valeur_fonciere"], rows: 15})
produce_histo = function(dvf){
const histo = Plot.plot({
style: {backgroundColor: "transparent"},
marks: [
Plot.rectY(dvf, Plot.binX({y: "count"}, {x: "valeur_fonciere", fill: "#ff562c"})),
Plot.ruleY([0])
]
})
return histo
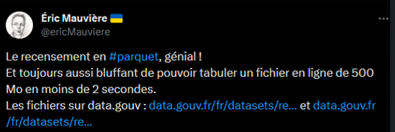
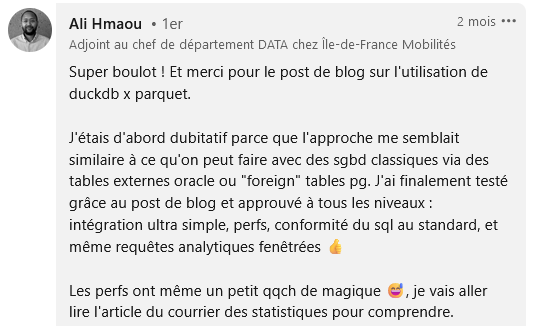
}Après Parquet: le recensement de la population (RP)
Retours utilisateurs après la première diffusion du RP en Parquet (fin 2023)


Références
Mauviere, Eric. 2024. « Comment bien préparer son Parquet ». 16 mai 2024. https://www.icem7.fr/outils/comment-bien-preparer-son-parquet/.