From ‘it worked on my notebook’ to production-ready machine learning
Bridging the gap with MLOps
2026-06-04
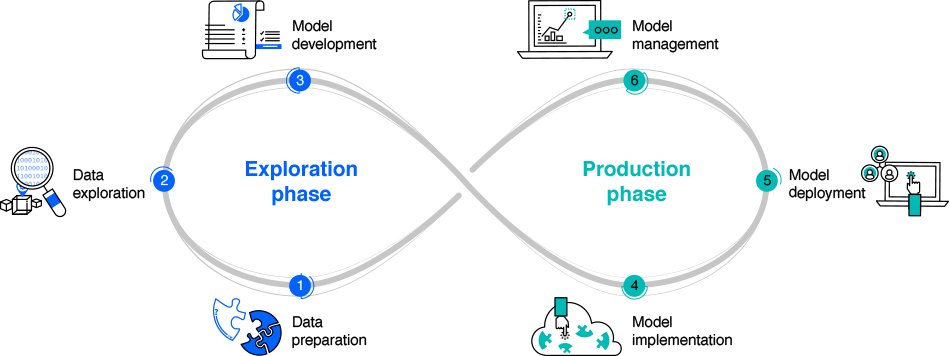
Fostering continuity
Source: ibm.com
- Applying and extending software development best practices
- DataOps: building robust data pipelines
- MLOps: deploying and maintaining ML models
Three lifecycles to master
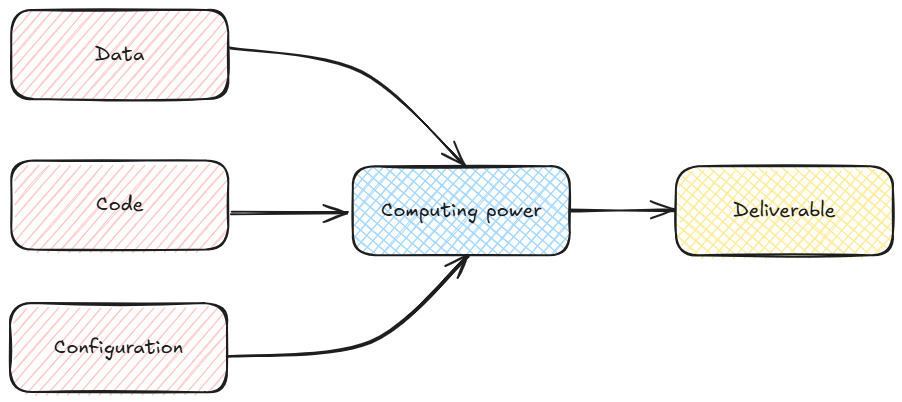
- A robust ML pipeline requires managing three independent lifecycles:
- Jupyter Notebooks does not separate them properly
Choosing appropriate tools
Code
Versioning (Git), improving quality with formatters (Ruff), community standard structure (cookiecutters)…
Configuration
Virtual environments and dependency management (uv), controlling external dependencies (Docker)…
Data
Standardised format (Parquet), cloud storage (S3), pipeline-oriented workflow (dbt)…
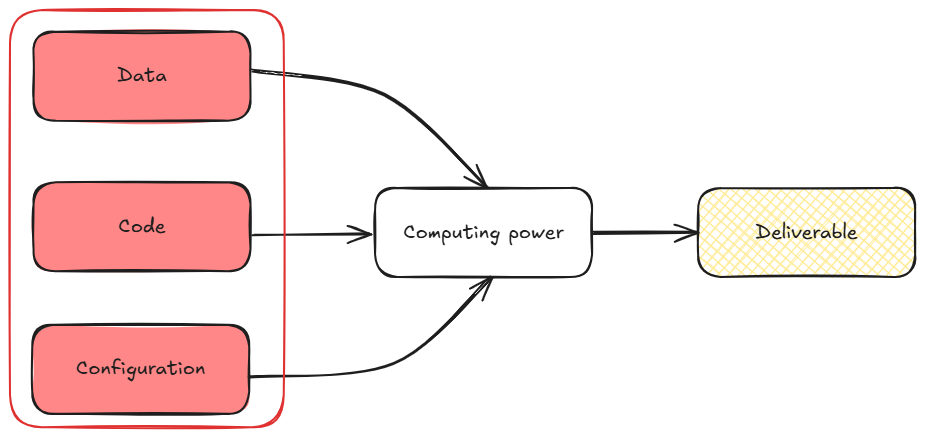
“It works on my machine”

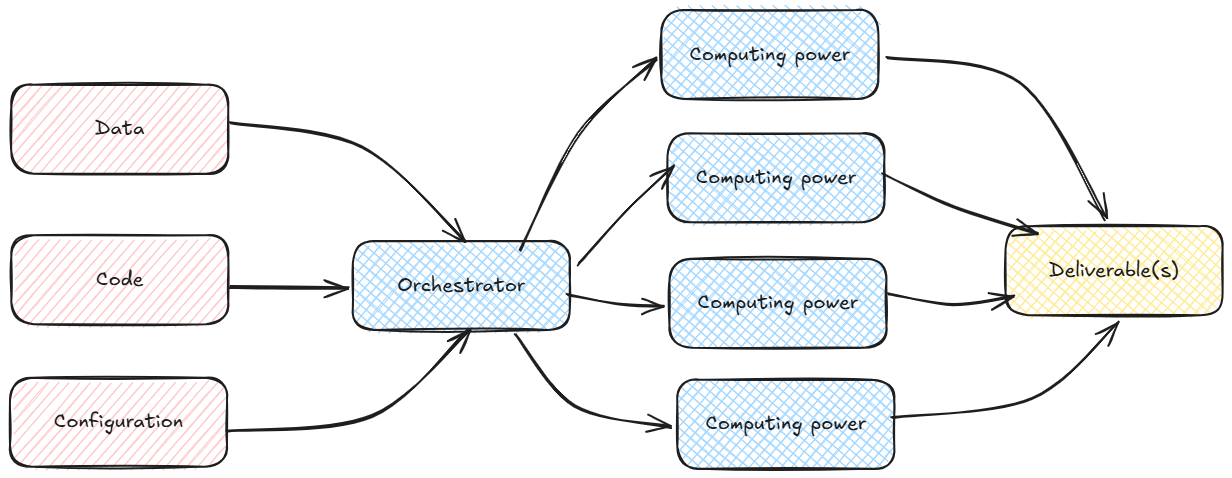
An industrialized project
Kubernetes turns individual containers into an industrialised, scalable fleet
Feedback loops and continuous improvement

- Monitoring is not optional: a model that worked at launch will degrade as the world changes
- Feedback loops close the gap between offline evaluation and real-world performance
- Good observability turns every production incident into a training signal